Is it possible to replace numerical weather prediction with deep learning? Certainly not yet. But first work is being done to investigate this question.
In this post I want to discuss a paper called “MetNet: A Neural Weather Model for Precipitation Forecasting” that Google Research published back in March 2020 and in which they try to forecast precipitation levels using only radar and satellite measurements. You can read the paper here and the accompanying blog post here.
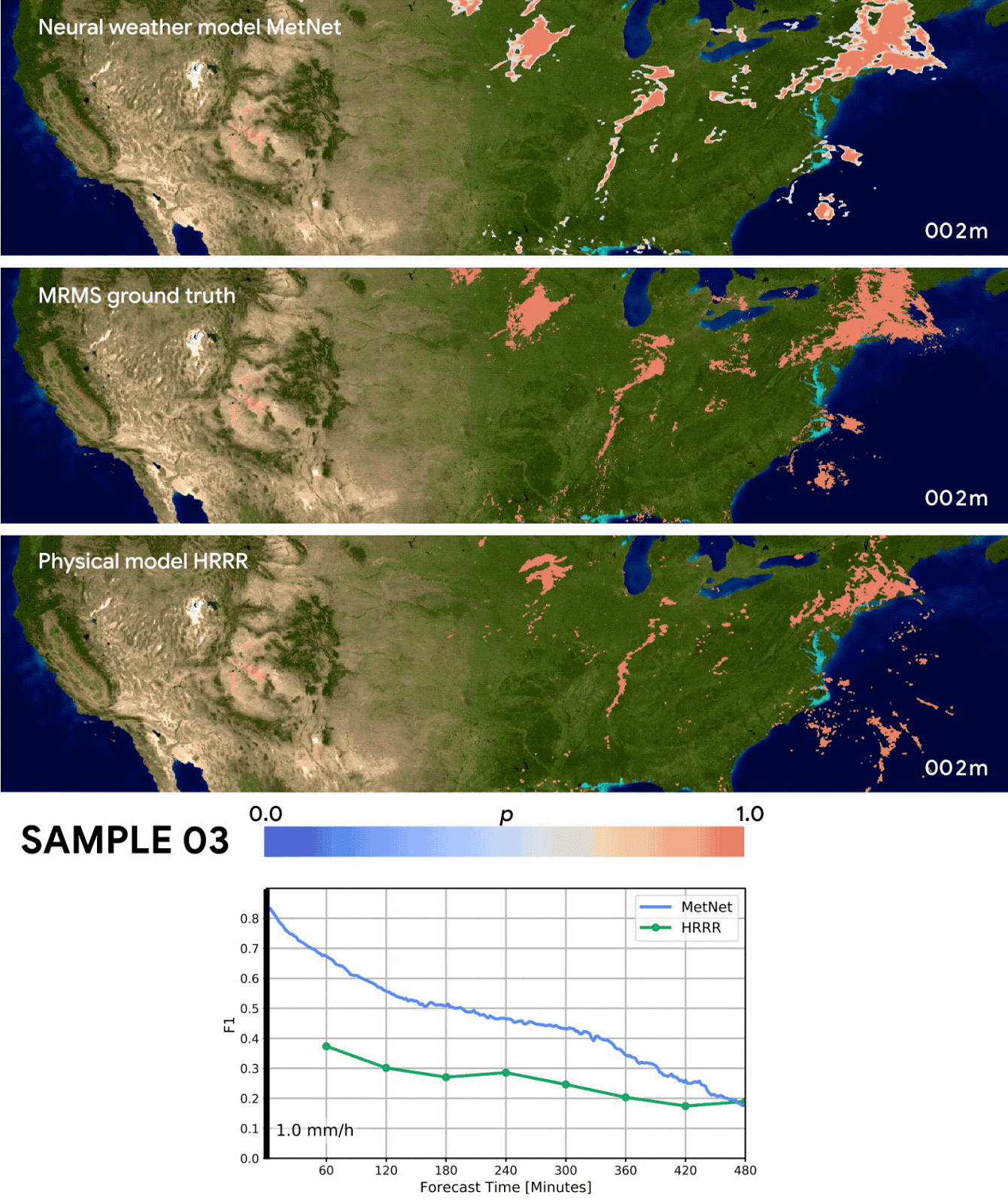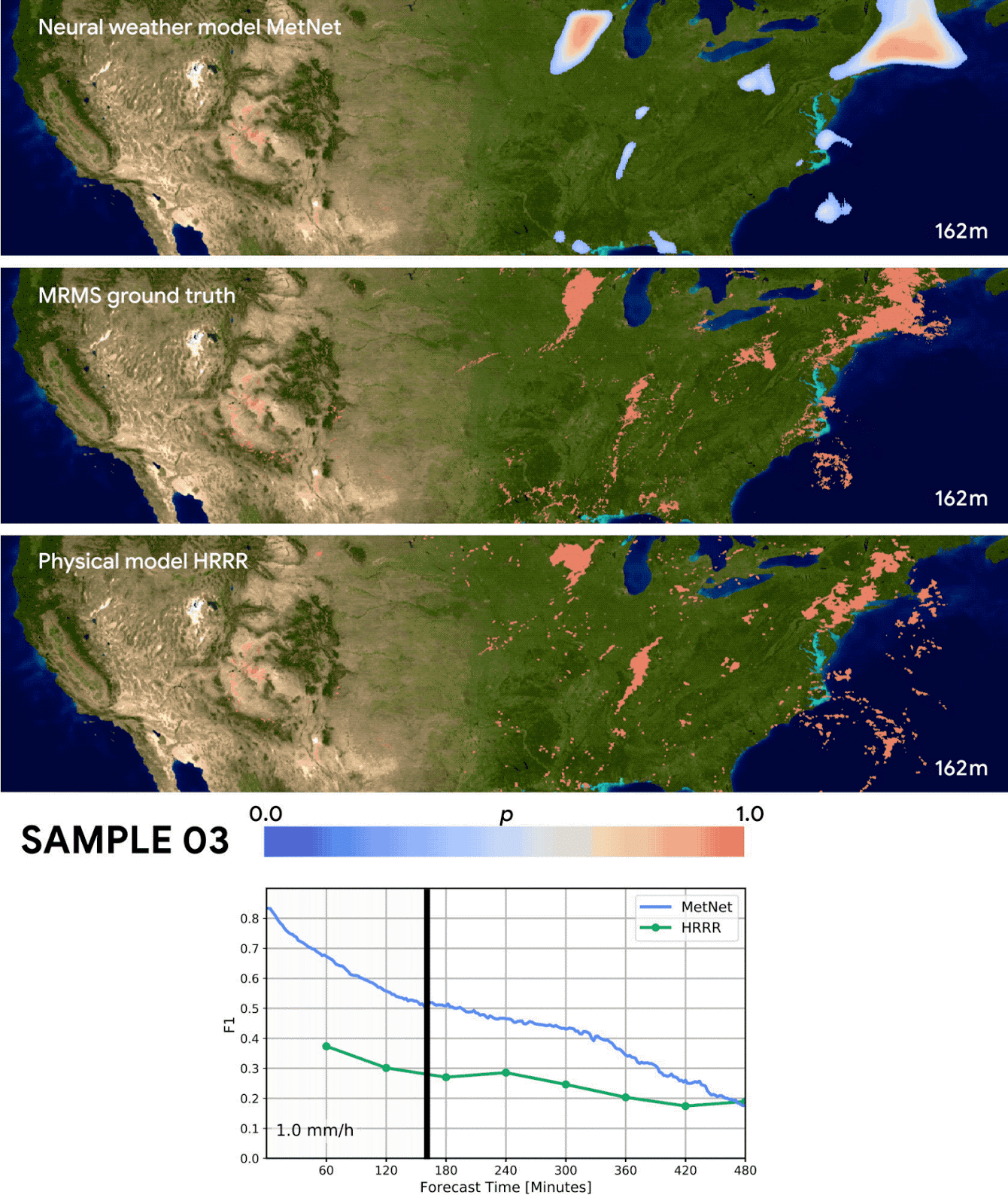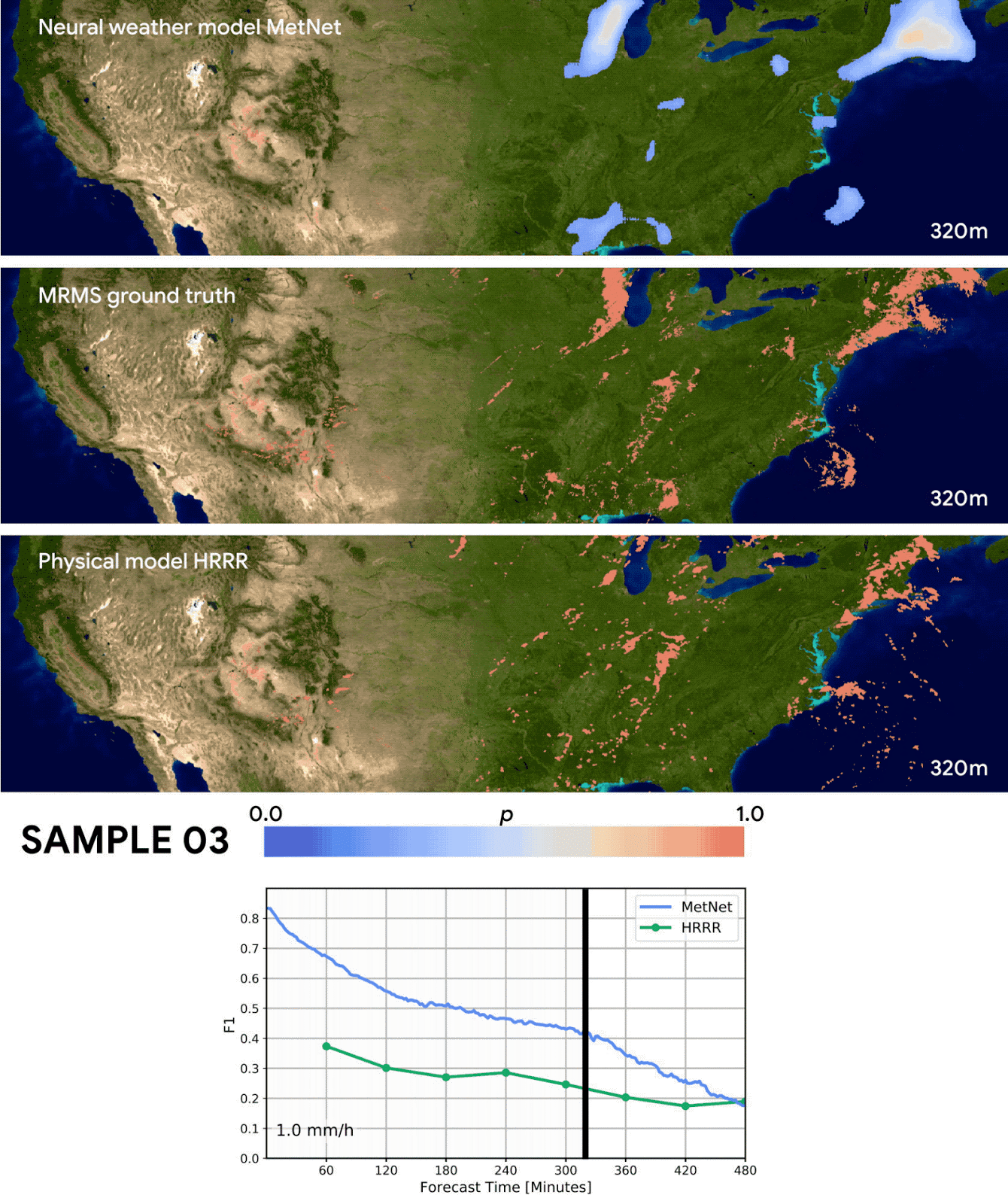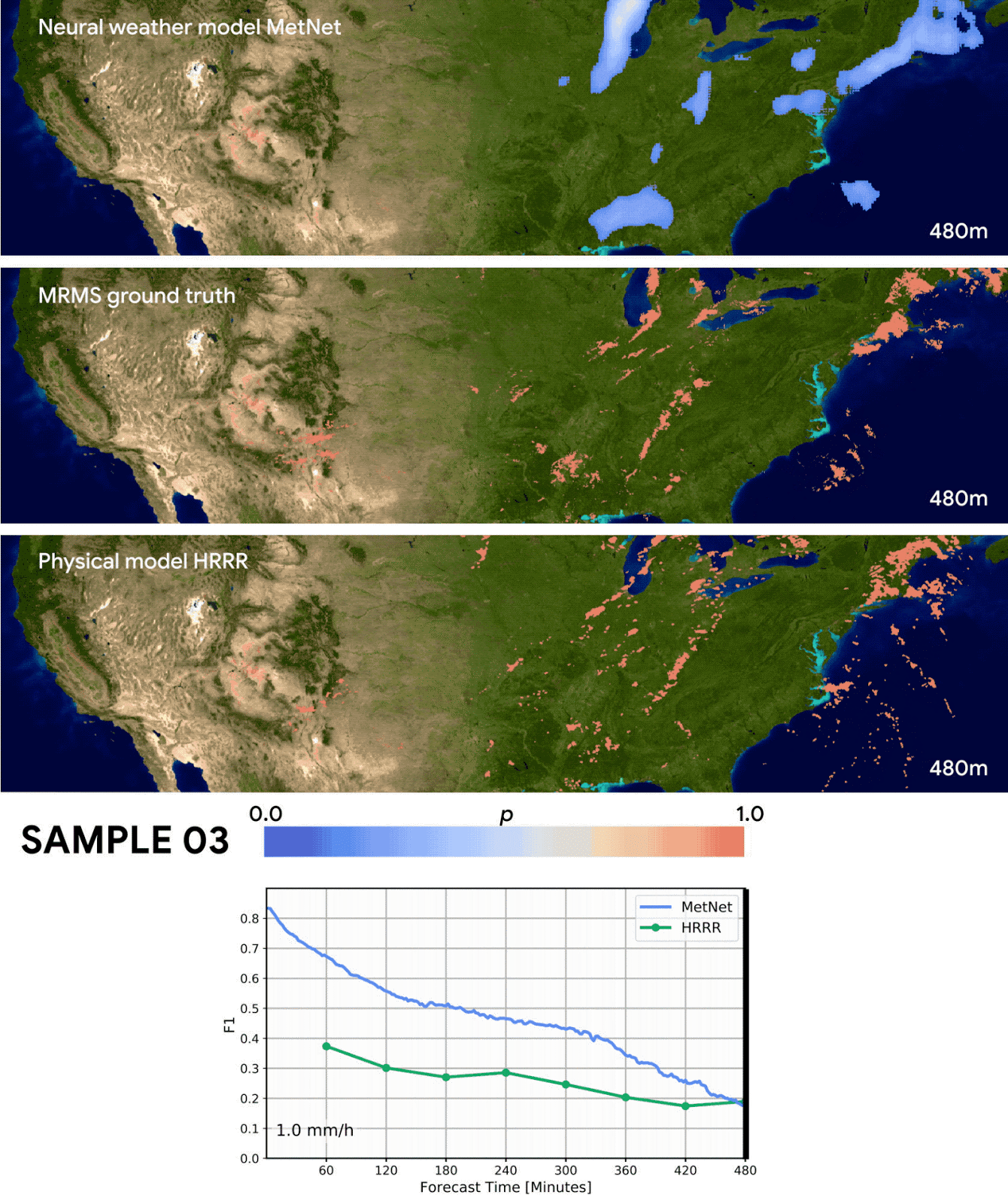
The results seem very promising as they are able to outperform both a classical NWP model (=numerical weather prediction using physics) and an optical flow approach up to eight hours into the future. I’m very glad Google is funding this research and consider this work an important achievement. But I also have some qualms about the way the MetNet forecasts were evaluated:
Their training set might have leaked into their test set.
In the paper’s appendix they talk about how they went about the evaluation:
For both MRMS and GOES we acquired data for the period January 2018 through July 2019. We split the data temporally into three non-overlapping data sets by repeatedly using approximately 16 days for training followed by two days for validation and two days for testing. From these temporal splits we randomly extracted 13,717 test and validation samples and kept increasing the training set size until we observed no over-fitting at 1.72 million training samples.
Metnet paper, p.14, Appendix A
It’s very understandable that they did it that way because it allows them to evaluate samples from a wide variety of different weather situations. And at a first glance it might seem fine because the test set is non-overlapping with the training/validation set. But on the other hand weather data has high auto-correlation. That means that a forecasting method that works well today will often also work well tomorrow but might not perform quite as good a year into the future. And the leakage problem might be exacerbated by the fact that the day of the month is included as a model feature. This information has probably no real predictive value but makes it easier to correlate the days in the training set with the ones from the test set.
I think it would have been much better to just split the data into three blocks: Use the first 80% as training data, next 10% as validation data and the next 10% as test data. This way of evaluating also avoids training on data from the future which is of course not possible in a production scenario.
The very best way would have been to train on a whole year and then evaluate on the next year, but they were probably missing the required data for that.
The forecasts from the baseline comparison could be made stronger
The Google research team spend quite a lot of effort finding/optimizing a good baseline forecasts, but there are still some relatively simple ways in which they could have been improved:
- The comparison forecasts could have been fitted to the target data using some sort of statistical post processing.
- Combining the two baseline forecasts would in all likelihood result in a forecast that’s better than both of its inputs
By doing that they could have evaluated against something much closer to the current state of the art and proved that their model is really a significant improvement over already existing approaches.
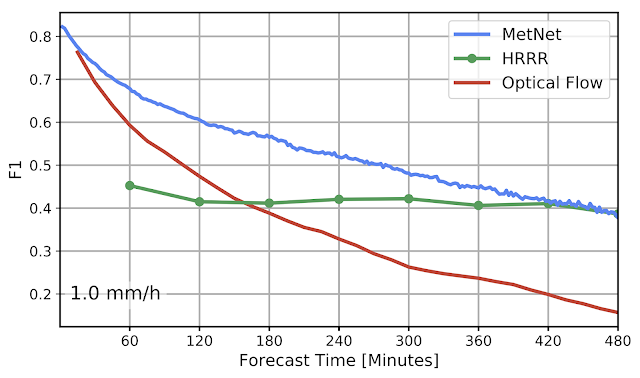
The comparison method is not totally fair
Forecasting skill in this paper is evaluated by predicting if the precipitation crosses a certain threshold and then calculating the F1 score. Converting the probablistic MetNet forecasts to a binary classification is done in the following way:
Since MetNet outputs probabilities, for each threshold we sum the probabilities along the relevant range and calibrate the corresponding F1 score on a separate validation set
Metnet paper, p.8, section 6.1
It’s a little unclear to me what they mean by “callibrating the F1 score”, but I think it’s something like “If the probability for precipitation > 1mm/h is bigger than 80% then we predict precipitation > 1mm/h”. In this example the 80% is the threshold that was calibrated. We don’t know what the actual thresholds are because they don’t mention them in the paper. Maybe there are also multiple different thresholds for different lead times or coordinates?
Irregardless of the actual details: This means that the MetNet forecasts are explicitly optimized for a high F1 score. But it’s not done for the baselines forecasts which might have been optimized for a totally different metric! For example: Maybe the NWP model was optimized mainly for “precision” and “recall” was only a secondary objective? Then this would penalized the F1 score where precision and recall have to be about the same for the best score.
A more fair comparison would have been to just take the median/mean of the MetNet probability distribution. Or alternatively to also optimize the baseline forecasts regarding the F1 score.
Things I would like to know more about
It’s understandable that Google Research does not want to share all of their hard earned research details and not publicize the weights of the neural net. But I think there are a few things that could have been included:
- What is the loss function with which the neural net is trained? Cross entropy? Or are they doing something more clever?
- How much compute is needed to train the model? They say that they used “up to 256 TPUs” but not for how long. It’s possible to make an educated guess though: The training data includes July 2019 and the paper was published March 2020. If we assume that they’ve run about 20 different experiments in that time-frame, then training a single model would take around 10 days at most. Or about 7 years on a single TPU.
- It would be interesting to know how well the probabilistic forecasts fit the real precipitation distribution. Do they have a similar shape?
Things I especially like about the paper
While I have some doubt about the evaluation methodology, the paper ist still pretty awesome. Here are some things I’m especially excited about:
- The use of “axial attention” to cut down on computing time is a cool idea. I think evaluating different attention mechanisms for weather prediction is an interesting research direction.
- Converting the regression problem into a classification problem by binning the target data is a very elegant way of getting probabilistic forecasts.
- Using a one-hot encoding for the lead times is an interesting idea. It seems a little bit counter-intuitive because just putting it in as float would probably help smooth over different lead times and make training more stable. But if there is enough training data this might not be an issue anyway and using a one-hot encoding is certainly much more expressive. I might steal that trick for my job at meteocontrol where we do solar power prediction.
What could be the next steps?
I think the MetNet approach has enormous potential. But it will only be significantly better than existing solutions if more data is integrated into the model. Right now it only has access to radar and satellite data and there is only so much you can do with this information. To get a more accurate forecast that works longer into the future you also have to look into things like air pressure/temperature and other atmospheric data which are driving the precipitation rates.
Of course that would require significantly more computing power: 3D weather data can get infamously big. But on the other hand MetNet has “only” 225 million parameters, while something like GPT3 has 175 Billion parameters, so improvements by scaling up are still technically feasible.
Further Ressources
- There is a very interesting presentation by one of the paper’s main authors where many additional details are clarified in the Q&A section:
- There is also a good discussion of the paper on youtube
- Thomas Capelle has implemented an open source version of MetNet. As of June 2021 there is no pretrained model available though. I’m very excited to see if the paper’s results will be reproduced by another team/institution in the future.

